
Muitas menções ontem:
Mas (no Twitter) esmagadoramente negativas:

|
|
|||
Muitas menções ontem:
Mas (no Twitter) esmagadoramente negativas:
Uma nova sondagem, aqui (o título da notícia está errado, dando 37,6% ao PS):
Intenções de voto:
PS: 36,7%
PSD: 23,7%
CDU: 13,2%
CDS-PP: 8,6%
BE: 6,6%
OBN: 11,2%
As nossas estimativas, calculadas da maneira já explicada, são as seguintes (entre parêntesis, evolução em relação a 8 de Outubro):
PS: 36,3% (+0,1)
PSD: 26,8% (-0,9)
CDU: 12% (+0,1)
CDS-PP: 7,9% (+0,1)
BE: 6,8% (=)
Logo, a nova informação acrescentada não sugere grandes mudanças, a não ser em relação ao PSD, começando a mostrar sinais de inversão da recuperação que o principal partido do governo vinha experimentando desde a crise política de Julho passado. O PSD já só está 1,7 pontos acima do seu mínimo em intenções de voto desde as eleições de 2011 (que foi de 25,1% no início de Julho de 2013). 26,8% representaria também, para o partido, caso fosse este um verdadeiro resultado eleitoral, o valor mais baixo desde 1976. A evolução das intenções de votos desde as últimas eleições legislativas pode ser vista aqui.
O Verbetes é um projeto desenvolvido no Labs Sapo UP e tem como objectivo identificar e extrair, de forma totalmente automática, pequenas biografias de personalidades mencionadas nas notícias. Visto que este processo é isento de qualquer intervenção humana, é imperativo garantir que os dados extraídos tenham o menor erro possível. A abordagem utilizada pelo Verbetes passa assim pelo uso e aplicação de padrões linguísticos. Estes padrões linguísticos são tipicamente construídos a partir de regras aplicadas a uma determinada estrutura lexical. Estas regras são necessariamente suportadas em técnicas de Processamento da Linguagem Natural.
São três as razões essenciais que corroboram a utilização destes padrões linguísticos e a reduzida taxa de erros resultante: (i) os padrões linguísticos são construídos especificamente para a extracção de nomes e cargos/profissões de textos noticiosos, garantindo assim um elevado grau de especificidade e consequentemente uma taxa de erros reduzida; (ii) dado que as notícias são textos com um estilo linguístico muito próprio e bem definido, é uma mais valia tirar partido desta homogeneidade. A aplicação de padrões linguísticos vai beneficiar deste facto no sentido de mais uma vez garantir uma taxa de erros reduzida; (iii) o uso de padrões linguísticos permite que cargos e profissões extraídos tenham maior granularidade, isto é, sejam mais completos e informativos, tal como “líder da bancada parlamentar do Partido Socialista” e não demasiado genéricos e abstractos como “político” ou “presidente”. Exemplos de padrões linguísticos incluem:
“O ex-primeiro-ministro, José Sócrates, (…)”
Estes padrões são aplicados a cada uma das frases da notícia e visam criar as fronteiras entre o nome e o cargo ou profissão a extrair. Um exemplo de padrão pode ser interpretado da seguinte forma: (i) a frase deve ser iniciada com um artigo definido masculino ou feminino singular; (ii) é opcionalmente seguida de um modificador (exemplo: ex, antigo, novo, vice, anterior, etc.); (iii) é seguida por um cargo ou profissão; (iv) é seguida por um nome próprio (simples ou composto por várias palavras e/ou partículas de ligação como “de” ou “e”) que deve ser precedido e sucedido de vírgulas; (v) e por fim o restante conteúdo da frase. Note-se que para a execução deste ou outro dos padrões linguísticos usados, são necessários recursos externos como analisadores morfológicos e listas de modificadores.
Para cada nome e respetivo cargo ou profissão extraído, é atribuído um intervalo temporal. Desta forma, é possível balizar os cargos das personalidades com base na data da notícia em que foi inicialmente identificado e na data da notícia em que foi extraído pela última vez. Esta informação é um bom indicador da data de início e fim do cargo ou profissão, contribuindo desta forma para a construção automática de biografias de personalidades referidas nas notícias.
Para além dos cargos ou profissões, o Verbetes extrai também nomes alternativos. Estes nomes correspondem a variações lexicais de uma entidade, muito frequentes nas notícias. Por exemplo, o nome “Aníbal Cavaco Silva” tem como nomes alternativos “Cavaco Silva” e “Cavaco”.
O projeto POPSTAR tira partido do Verbetes no sentido em que tem à disposição uma vasta lista de personalidades mencionadas nas notícias portuguesas e as suas varições lexicais (nomes alternativos). Com base nesta informação, é assim possível calcular, por exemplo, o buzz de “Pedro Passos Coelho” nas notícias. Adicionalmente, pelo facto de existirem várias personalidades com o mesmo nome mas cargos ou profissões distintas, o Verbetes é uma forma adicional de apoiar a desambiguação de menções a personalidades em notícias.
Mais informações sobre o projeto disponíveis em: http://labs.sapo.pt/2011/02/verbetes/
Utilizar o Twitter para tentar recolher tweets escritos por utilizadores com certas características, nomeadamente utilizadores portugueses, e que falem sobre certos tópicos/entidades no meio de tantos tweets publicados por minuto, é uma tarefa complexa. Dada a natureza do Twitter é comum encontrarmos tweets que são escritos por ro(bots) como por exemplo, tweets automáticos de apps autorizadas, ou tweets de jornais como @Público. Outro problema, são as menções ambíguas como “portas, “passos, ou “seguro”. Neste post vamos vamos assumir que temos uma lista de tweets escritos por humanos e em língua portuguesa. Queremos seleccionar automaticamente tweets que mencionem explicitamente Pedro Passos Coelho. Exemplos:
“o que é feito do passos? Já voltou do méxico?”
“fui ao Passos Manuel e não te vi lá!”
“Passos afirma que OE pode gerar conflito de expectativas.”
“de irrevogável em irrevogável, passos lá se aguenta -__-”
“fiquei a 2 passos mas não consegui ![]() “
“
Estes exemplos ajudam-nos a explicar a complexidade da tarefa. A linguagem no Twitter é bastante informal e o limite de 140 carácteres faz com que grande parte dos utilizadores escrevam uma menção simples “Passos” em vez de “Passos Coelho” ou “Pedro Passos Coelho”. Muitas vezes nem sequer é utilizado o nome com letra maíuscula. Para complicarmos ainda mais a situação, há a questão da ambiguidade do nome. A palavra “seguro” refere-se a António José Seguro ou ao seguro automóvel? “Jerónimo” é o líder do PCP ou é uma referência à empresa Jerónimo Martins? “Cavaco”, “Passos” e “Portas” são outros exemplos típicos de menções ambíguas quando queremos seguir tweets sobre políticos nacionais.
No âmbito do POPSTAR criámos um filtro de desambiguação no qual são aplicadas técnicas de processamento de linguagem natural, recuperação de informação e aprendizagem computacional. Estudámos um grande número de características (ou pistas) que utilizámos para ensinar o computador a perceber a relação entre uma dada entidade (por exemplo AJS) e um tweet. Este grupo de características inclui 1) todas as palavras dos tweets, similaridades de palavras do tweet e a página da Wikipédia da entidade ou páginas web oficiais da entidade; 2) a relevância de certas palavras no tweet quando comparado com todas as palavras na lista de tweets (TF-IDF é uma técnica típica dos motores de pesquisa); 3) hashtags e conteúdo das páginas apontadas por URLs nos tweets.
Uma vez extraídas as características mencionadas anteriormente e utilizando o conjunto de tweets anotados manualmente (abordagem supervisionada), podemos treinar algoritmos típicos de aprendizagem computacional (e.g. SVM, Random Forest, Naive Bayes) para ensinar o computador a distinguir tweets ambíguos.
A equipa do POPSTAR aplicou esta abordagem na competição de Filtering do RepLab 2013 tendo obtido o primeiro lugar com 91% de acerto em mais de 140000 tweets sobre 61 entidades diferentes. Mais detalhes na nossa estratégia de resolução de nomes ambíguos no Twitter, aqui.
Um dos objectivos do projecto POPSTAR é construir um sistema capaz de processar um texto indicando se estão mencionados actores políticos e qual o sentimento expresso em relação a eles. A nossa noção de sentimento é simplista: um texto pode conter uma opinião positiva, negativa ou neutra. A ausência de opinião ou sentimento é considerada também ela neutra.
Mas como podemos implementar este sistema? À primeira vista parece uma tarefa muito complicada – uma máquina entender mínimamente uma opinião ou um estado de espírito humano – e, de facto, é.
A primeira abordagem que talvez nos ocorra é escrever um conjunto de regras gramaticais. Por exemplo, no nosso caso queremos o sentimento em relação a um político portanto podemos começar com regras simples deste género:
Para isto precisamos de uma lista de palavras boas e más, a que chamamos um léxico de polaridade ou sentimento. Um exemplo sofisticado é o SentiLex http://dmir.inesc-id.pt/
Esta abordagem baseada em regras tem dois problemas principais: o enorme trabalho manual exigido e fraca robustez. Quando digo fraca robustez quero dizer que as regras estão normalmente pensadas para um certo tipo de texto, sem erros ortográficos e com frases relativamente simples. Saindo desses moldes a performance do sistema cai. Num ambiente como a Internet a escrita é informal e muito criativa (chamemos-lhe assim), o que faz com que seja díficil definir regras generalistas.
“Basta!!!!!!….qualquer pessoa de bom senso sabe que o Sr Barroso apenas representa os interesses Neoliberais…..ele obedece fielmente ao dono …lindo menino!!” – Paulo Vilarinho, comentários do Público
Outra abordagem ainda mais simples que podemos usar, é uma contagem de palavras positivas e negativas. Temos um texto, temos listas de palavras boas e más, contamos quantas palavras boas e quantas palavras más aparecem e consoante as que estiverem em maior número, atribuímos uma polaridade. Podemos até usar esta abordagem como plano de contingência no caso das regras, quando nenhuma se aplicar.
Basta olhar para o exemplo acima para perceber que esta abordagem tem sérias limitações. Embora haja claramente uma maioria por parte das palavras positivas, o sentimento do texto é também claramente negativo. A solução para este problema tem de ser mais sofisticada. Para além das palavras é preciso olhar para a pontuação, é preciso dar mais importância a certas palavras e menos a outras, é preciso considerar o contexto.
Mas como podemos definir o que quer dizer mais ou menos pontuação? E que pesos devemos dar às palavras? No fundo, como podemos relacionar os vários aspectos do texto com a sua polaridade? Uma possível resposta é: deixamos a máquina aprender e descobrir essas relações.
Num futuro post explicaremos como podemos ensinar a máquina. Não percam o próximo episódio! Se não quiserem esperar, podem fazer batota, está no Q&A uma secção sobre isto.
Aplicando para cada líder político o método descrito na entrada anterior, dificuldades inesperadas surgiram no caso de António José Seguro. Olhando para os dados, percebe-se a fonte dos problemas.
Como se pode ver no gráfico, com dados até meados de Setembro, a correlação do índice de popularidade da Eurosondagem com o índice das outras casas é negativa. Se admitirmos que existe uma variável latente que explique estes dados, chamemos-lhe Avaliação de Seguro, então, perante uma melhoria da Avaliação de Seguro, o modelo vai prever efeitos opostos na Eurosondagem e nas restantes casas.
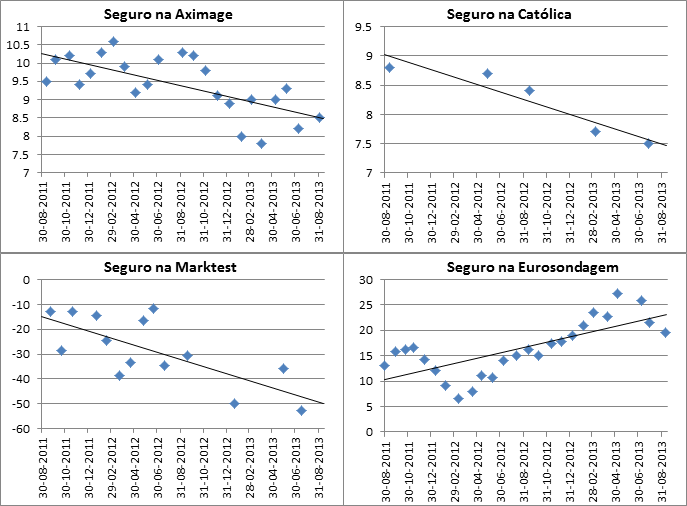
Por outras palavras, suponham que, contas feitas, a Avaliação de Seguro tem correlação positiva com o índice de popularidade da Eurosondagem e negativa com as restantes casas. Assim, quando o Seguro subisse nos inquéritos da Marktest, da Católica ou da Aximage, o nosso modelo iria automaticamente considerar que a Avaliação de Seguro desceu. Convenhamos que não seria muito razoável.
Para resolver este dilema considerámos a hipótese de construir dois índices distintos. Um com base na Eurosondagem e outro com base nas restantes casas. Basicamente, sempre que um índice subisse o outro desceria e o leitor que escolhesse em qual acreditar Acabámos por rejeitar esta solução e optámos por estimar o Filtro de Kalman
impondo a restrição de os coeficientes associados à variável latente serem positivos. Assim, evita-se o paradoxo de ter uns índices sistematicamente a descer e a ter a nossa Avaliação de Seguro sistematicamente a subir. Não é a solução ideal, longe disso. Por esse motivo, os nossos índices sobre a Avaliação de Seguro devem ser lidos com toda a precaução e admitindo que podem estar totalmente errados.
No futuro, com novos dados, tentaremos rever as nossas contas e encontrar uma solução mais satisfatória.
A nossa análise baseia-se no pressuposto de que há uma variável não observada, a que podemos chamar avaliação dos líderes políticos, que influencia os resultados de cada uma das casas. E, para manter o exercício simples, admitimos que essa relação é linear. Assim, o índice de popularidade construído pela casa de sondagens i, no momento t, terá a seguinte relação com a avaliação, que não observamos:
Popularidadei,t = αi + βi Avaliaçãot + εi,t. (1)
Infelizmente, a variável em que estamos interessados é aquela que não se observa, a Avaliação. Para a estimar, temos de admitir alguns pressupostos sobre o seu comportamento e depois conjugar com a equação (1) — repare que temos várias equações: uma por cada casa de sondagens. No nosso modelo econométrico, pressupomos que
Avaliaçãot = Avaliação t-1 + ut. (2)
Com todas estas equações, podemos usar o filtro de Kalman** para estimar uma série temporal com os valores da variável subjacente, a tal Avaliação dos Líderes Políticos. Finalmente, convertemos este índice de popularidade obtido numa numa escala de 0 a 20.
O gráfico com a Avaliação dos Líderes Políticos que podem encontrar no Popstar, é assim obtido.
* No caso da Católica e da Aximage, usamos a escala que propõem, no caso das outras duas usamos o saldo de respostas positivas e negativas.
** Os princípios base não diferem muito dos que já foram explicados aqui. A principal diferença é que não podemos tratar as casas de sondagem uniformemente.
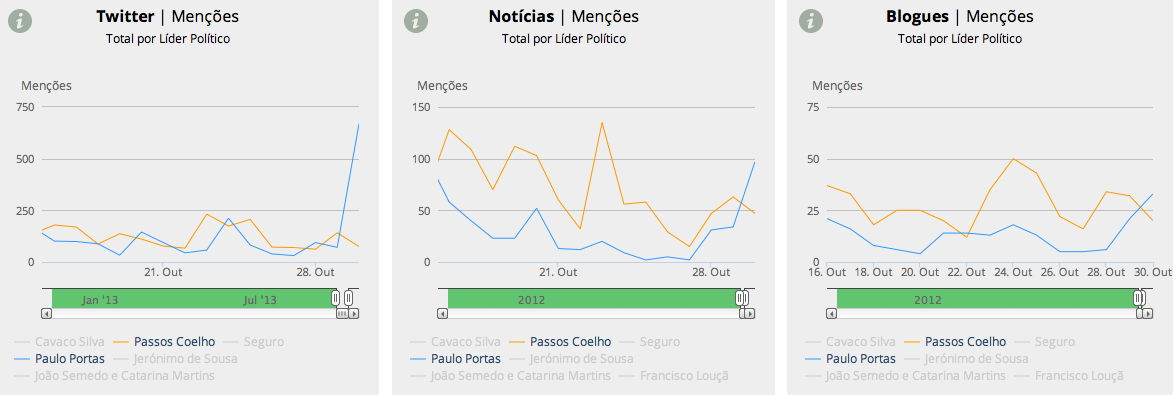
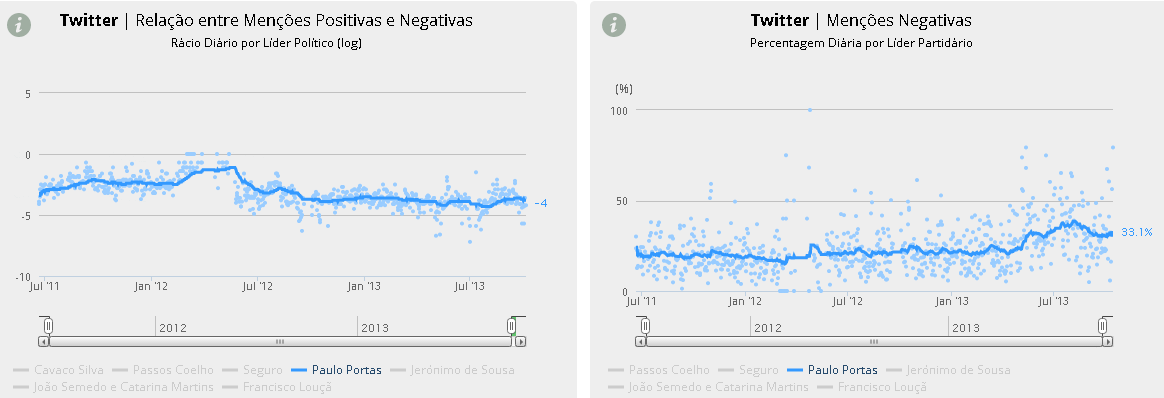
Previsivelmente, entre os líderes político-partidários, Paulo Portas dominou o buzz de ontem, dominância particularmente acentuada no Twitter e nas notícias (mas curiosamente menos nos blogues):

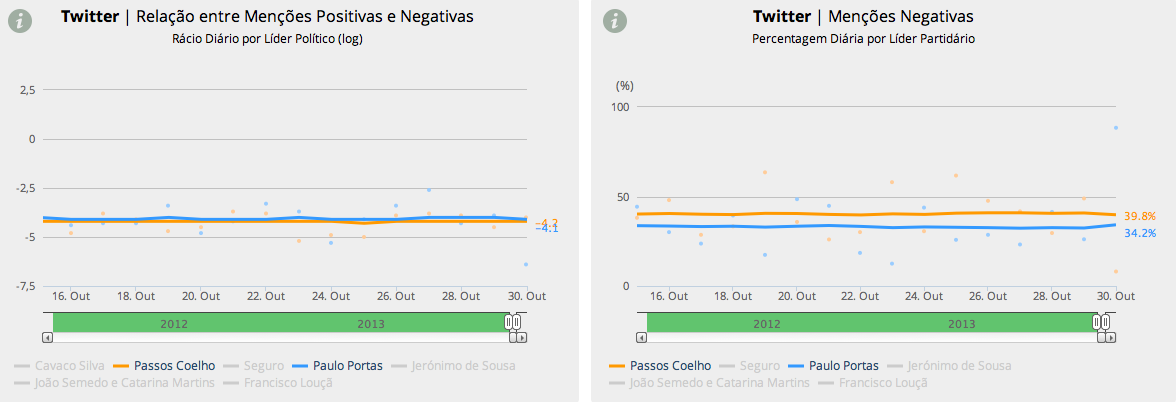
No “sentimento” do Twitter (opiniões positivas, negativas ou neutras), a prova de uma quase invariável regularidade: quantas mais menções no Twitter cuja polaridade se consiga medir como positiva ou negativa, mais acentuada a sua negatividade. Apesar do smoother (por definição e da maneira como está calculado) não mostrar isso ainda, pode ver-se nos pontos do gráfico como o (log do) rácio entre menções positivas e negativas para Portas foi particularmente negativo ontem e como o vice-Primeiro Ministro foi objecto de mais de 70% de todas as menções negativas feitas a todos os líderes partidários.
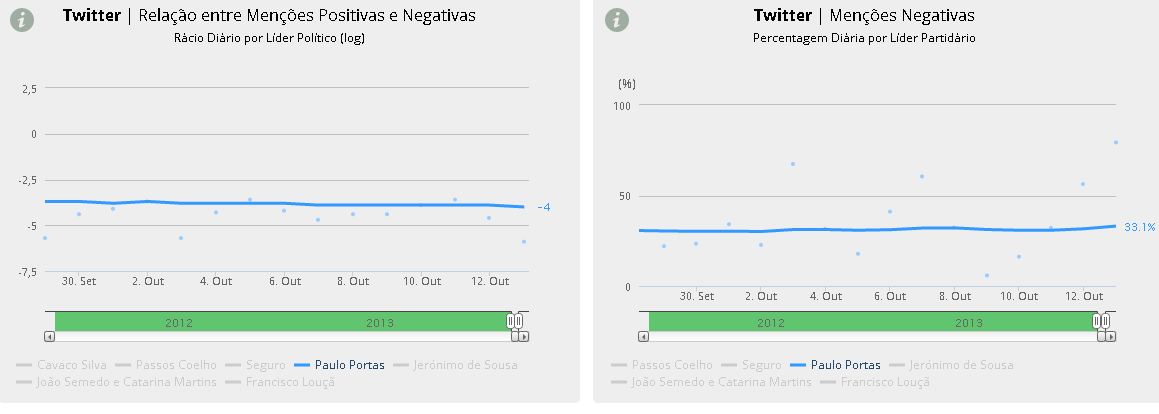
Contudo, esta linha só começará a inclinar-se decisivamente para baixo (no rácio) ou para cima (no share de menções negativas) se este padrão tiver continuidade nos próximos dias. Como se vê nos gráficos de mais longo prazo, essas mudanças mais permanentes não se manifestam com muita frequência. O sentimento no Twitter em relação a Portas degrada-se em Julho de 2013 (com diminuição do rácio positivas/negativas e aumento do share de menções negativas) mas volta a subir (rácio) e descer (share) a partir de Agosto, de resto, como sucedeu, afinal, na avaliação da sua actuação nas sondagens.
Nova sondagem divulgada hoje pelo Expresso:
Eurosondagem, 2-8 Outubro, N=1010, Tel.
PS: 36,5%
PSD: 26.9%
CDU: 12.1%
CDS: 8.6%
BE: 5.9%
Em relação à última sondagem conhecida (a da Aximage), o PSD desce, apesar de subir em relação ao anterior resultado da Eurosondagem. O resultado é que, no fundamental, a nossa estimativa para o PSD permanece praticamente inalterada. O mesmo sucede com o CDS, que também desce em relação à Aximage mas sobe em relação ao último estudo da Eurosondagem. Na popularidade, a única mudança mais expressiva é a descida de Passos Coelho.
Desde a crise política de Julho, o que sucedeu no nosso filtro?
1. PSD subiu 2.1 pontos, de 25.6% para 27.7%.
2. CDS desceu 1.2 pontos, de 9% para 7.8%.
3. PS subiu 1.3 pontos, de 34.9% para 36.2%.
4. CDU manteve-se praticamente inalterado (de 12.2% para 11.9%).
5. BE desceu 1.6 pontos, de 8.4% para 6.8%.
Na popularidade, tudo relativamente estável nos últimos meses, excepto Paulo Portas: queda abrupta após a crise política mas sinais de recuperação desde o início de Setembro.
A lista de leituras de ciência política recomendadas relacionadas com o que estamos a fazer no POPSTAR aumenta drasticamente: New Directions in Analyzing Text as Data, uma conferência recente na LSE (onde a Nina também esteve). Particularmente apelativo (para mim): “Predicting and Interpolating State-level polling using Twitter textual data”, de Nick Beauchamp (uma pessoa diz que não está necessariamente interessada no Twitter como instrumento de previsão mas depois vai-se a ver e não resiste).